
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Google OAuth
- factory
- spring security
- java
- Spring
- Volatile
- 일급 컬렉션
- 일급 객체
- Dependency Injection
- builder
- lombok
- synchronized
- OAuth 2.0
- Today
- Total
HJW's IT Blog
[CodeIt] 8월 5주차 본문
데이터의 특성 구하기
SELECT COUNT(email) FROM copang_main.member;
→ 모든 회원은 이메일을 가지니 총 회원 수를 알 수 있다
→ null 은 count 에 포함되지 않는다
SELECT COUNT(*) FROM copang_main.member;
→ member 테이블의 총 row 수를 반환한다
SELECT MAX(height) FROM copang_main.member;
→ height 값이 가장 큰 member 를 반환
SELECT MIN(weight) FROM copang_main.member;
→ weight 값이 가장 작은 member 를 반환
SELECT AVG(weight) FROM copang_main.member;
→ weight 값의 평균을 반환한다
→ null 포함 x
- SUM() → 합산
- STD() → 표준편차
- ABS() → 절대값
- SQRT() → 제곱근
- CEIL() → 올림
- FLOOR() → 내림
- ROUND() → 반올림
NULL 다루기
SELECT * FROM copang_main.member WHERE address IS NULL;
→ address 값이 null 인 row 를 반환한다
→ NULL 이 아닌 값을 반환하고 싶다면 IS NOT NULL
- COALESCE
- 합치다 라는 의미
- COALESCE(height, ‘####’)
- height 값이 있다면 그 값을, 없다면 #### 을 반환
- IS NULL 과 = NULL 은 다르다
- NULL 은 무언가와 비교할 수 있는 대상이 아니다
이상한 값 제외하기
SELECT AVG(age) FROM copang_main.member WHERE age BETWEEN 5 AND 100;
→ 5 ~ 100 값 사이의 age 의 평균
→ 즉 위 조건을 만족하지 않는다면 계산에서 제외
컬럼끼리 계산하기
SELECT
email,
CONCAT(height, 'cm', ', ' , weight, 'kg') AS '키와 몸무게',
weight / ((height/100) * (height/100)) AS BMI
FROM copang_main.member;
→ 위와 같이 컬럼끼리 산술계산이 가능하다
→ 계산에 null 이 하나라도 들어간다면 null 이 반환된다
→ AS 문을 통해 alias 를 추가할 수 있다
→ CONCAT 함수로 하나의 컬럼으로 만들 수도 있다
컬럼 값 변환해서 보기
SELECT
email,
CONCAT(height, 'cm', ', ' , weight, 'kg') AS '키와 몸무게',
weight / ((height/100) * (height/100)) AS BMI
(CASE
WHEN weight IS NULL OR height IS NULL THEN 'null'
WHEN weight / ((height/100) * (height/100)) >= 25 THEN '비만'
WHEN weight / ((height/100) * (height/100)) >= 18.5 AND weight / ((height/100) * (height/100)) < 25
THEN '정상'
ELSE '저체중'
END) AS obesity_check
FROM copang_main.member;
→ BMI 계산을 토대로 과체중, 정상, 저체중을 반환하는 컬럼을 생성한 것이다
고유값만 보기
SELECT DISTINCT(SUBSTRING(address, 1, 2) FROM copang_main.member;
→ address 컬럼의 값에서 가장 첫 문자부터 총 두개의 문자를 추출하여, distinct 한 값을 반환한다
- LENGTH() → 문자열 길이
- UPPER, LOWER() → 대소문자
- LPAD, RPAD() → 문자열의 왼쪽 혹 오른쪽을 특정 문자로 채우는 하뭇
- TRIM, LTRIM, RTRIM → 문자열 공백 제거
Grouping
SELECT gender, COUNT(*), AVG(height), MIN(weight) FROM copang_main.member GROUP BY gender;
→ count, avg 등은 모두 각 그룹을 대상으로 실행된다
SELECT SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2),
gender;
→ 지역별 count 를 반환받을 수 있다
→ 그루핑 기준으로 여러컬럼을 사용할 수 있다
→ ex) 같은 지역에 살더라도 성별에 의해 다른 그룹으로 나뉜다
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING
region='서울'
AND gender='m';
→ 특정 값에 따라 필터링
→ WHERE : 테이블에서 row를 조회할때 조건을 설정
→ HAVING 은 조회된 row 들을 grouping 할때 다시 필터링
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM member
GROUP BY SUBSTRING(address, 1, 2), gender WITH ROLLUP
HAVING region IS NOT NULL
ORDER BY region ASC, gender DESC;
→ WITH ROLLUP : 위의 결과는 성별 구분없이 region 컬럼을 기준으로만 count 한 값도 반환한다
여러 테이블 다루기
- FK : 테이블의 여러 컬럼중 다른 테이블의 특정 row 를 식별할 수 있게 해주는 컬럼
- JOIN → 여러 테이블을 합쳐 하나로 보이도록
SELECT
item.id,
item.name,
stock.item_id,
stock.inventory_count
FROM item LEFT OUTER JOIN stock
ON item.id = stock.item_id;
→ item 테이블을 기준으로 stock 테이블을 합치라는 의미
→ 기준: item.id = stock.item_id
→ 서로 값이 같은 row 끼리 가로 방향으로
A LEFT OUTER JOIN B → A 의 모든 데이터 + A + B 의 중복 데이터
A RIGHT OUTER JOIN B → B의 모든 데이터 + (A&B) 의 중복 데이터
inner join → 두 테이블이 모두 가지고 있는 데이터만
SELECT
i.id,
i.name,
s.item_id,
s.inventory_count
FROM item AS i RIGHT OUTER JOIN stock AS s
ON i.id = s.item_id;
→ 위처럼 테이블에도 alias 를 붙일 수 있다
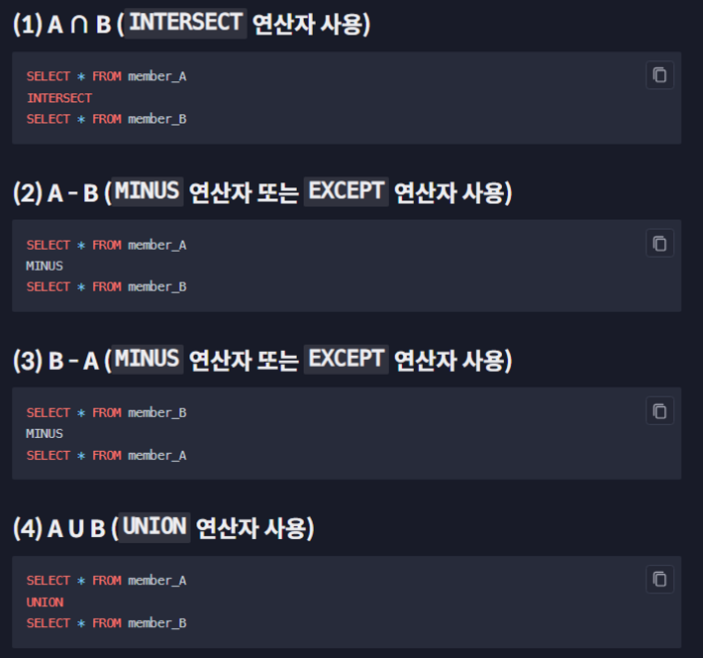
같은 종류의 테이블 조인
→ 상황 : 기존 테이블을 대체할 새로운 테이블을 만들었는데, 원래 있던 데이터가 모두 포함되었는지 확인해야 하는 상황
SELECT
old.id AS old_id
old.name AS old_name
new.id AS new_id
new.name AS new_name
FROM item as old LEFT OUTER JOIN item_new AS new
ON old.id = new.id;
- UNION
- 합집합 연산 →
- 해당하는 영역의 row 들은 중복을 제거하고 딱 하나의 row 만 보여준다는 문제
- UNION ALL 을 사용
- 합집합 연산 →
3개의 테이블합치기
SELECT
i.name, i.id,
r.item_id, r.star, r.comment, r.mem_id,
m.id, m.email
FROM item AS i LEFT OUTER JOIN review AS r
ON r.item_id = i.id
LEFT OUTER JOIN member AS m ON r.mem_id = m.id;
→ item & review 의 join 후 해당 결과와 member 테이블과 join 하게 된다.
의미 있는 데이터 추출하기
SELECT
i.id, i.name, AVG(star), COUNT(*)
FROM item AS i LEFT OUTER JOIN review AS r
ON r.item_id = i.id
LEFT OUTER JOIN member AS m ON r.mem_id = m.id
WHERE m.gender = 'f'
GROUP BY i.id, i.name
HAVING COUNT(*) > 1
ORDER BY AVG(star) DESC;
→ 각 상품별로 여성회원들이 남긴 별점의 평균값
→ 2개 이상의 별점 수
→ 별점 내림차순 정렬
서브쿼리
SELECT i.id, i.name, AVG(star) as avg_star
FROM item as i LEFT OUTER JOIN review as r
ON r.item_id = i.id
GROUP BY i.id, i.name
HAVING avg_star < (SELECT AVG(star) FROM review)
ORDER BY avg_star DESC;
- 쿼리 하나가 큰 쿼리의 부품처럼 사용되고 있다
- 즉, 전체 sql 문에서 일부를 이루는 sql문이다
- 서브쿼리는 괄호로 감싸야 한다
SELECT
id,
name,
price,
(SELECT MAX(price) FROM item) AS max_price
FROM copang_main.item;
SELECT * FROM item
WHERE id IN
(
SELECT item_id
FROM review
GROUP BY item_id HAVING COUNT(*) >=3
);
- 위와같이 서브쿼리에 alias를 붙일수도, SELECT, WHERE 문내에서도 사용할 수 있다
- ANY → ~중 하나라도 (SOME 과 같은 역할을 한다)
- ALL → 모두 만족해야 한다
FROM SUBQUERY
SELECT AVG(review_count)
FROM
(
SELECT
SUBSTRING(address, 1, 2) AS region,
COUNT(*) AS review_count
FROM review AS r LEFT OUTER JOIN member AS m
ON r.mem_id = m.id
GROUP BY SUBSTRING(address, 1, 2)
HAVING region IS NOT NULL AND region !='안드') AS review_count_summary;
- 서브쿼리로 생성된 테이블 = derived table
- derived table 은 반드시 alias를 가져야 한다
서브쿼리의 중첩 & 문제점
- 서브쿼리를 여러번 중첩할 수 있다
- 하지만 이러한 방식은 너무 길어서 읽기 힘들어 진다는 문제점이 발생한다
- 중복또한 존재할 수 있다
- 그렇기에 view 를 사용한다
- view 란? → join 과 같은 작업을 하여 가상으로 만드는 결과 테이블
CREATE VIEW three_tables_joined AS
SELECT i.id, i.name, AVG(star) AS avg_star, COUNT(*) AS count_star
FROM item AS i LEFT OUTER JOIN review AS r on r.item_id = i.id
LEFT OUTER JOIN member AS m ON r.mem_id = m.id
WHERE m.gender = 'f'
GROUP BY i.id, i.name
HAVING COUNT(*) >= 2
ORDER BY AVG(star) DESC, COUNT(*) DESC;
SELECT * FROM three_tables_joined;
- 위와 같이 선언 및 조회가 가능하다
- view 를 사용하게 되면 가독성이 훨씬 나아진다
- view 와 table 의 차이 → view 는 사용자에게 높은 편의성, 상황에 알맞은 데이터 분석 기반 구축 , 데이터 보안을 제공한다