
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- lombok
- Volatile
- 일급 컬렉션
- Google OAuth
- spring security
- Dependency Injection
- Spring
- factory
- 일급 객체
- OAuth 2.0
- builder
- synchronized
- java
Archives
- Today
- Total
HJW's IT Blog
[CodeIt] 9월 2주차 본문
데이터베이스 모델링
- 개발자는 데이터를 어떻게 저장할지 설계해야 한다
- 어떻게 저장할지 결정하는 과정을 데이터 모델링이라 한다
- 개념적 구조에 대한 설계 → 논리적 모델링
- 데이터베이스 구축에 필요한 것을 정하는것 → 물리적 모델링
데이터 모델
- 데이터를 사용하려는 목적에 맞게 정리하고 체계화 해놓은 모형
- 데이터를 row , col 로 나누고, table 사이의 관계를 FK로 표현한다
Entity : 개체
- 저장하고 싶은 데이터의 대상
- 실제 대상 하나 하나를 뜻한다 → row 하나를 뜻한다
- 일반화 하여 이야기 할 때는 Entity Type (Table 전체) 를 의미한다
Attribute : 속성
- 각 entity 에 대해 저장하려는 내용
- ex) 학생 → 학번, 이름, 성별, 입학년도, 전공
Relationship : 관계
- Entity 사이의 연결점
- ex) 학생, 수업, 교수 entity 가 있을때, 학생은 수업을 듣는다, 교수는 수업을 가르친다 등의 관계가 있다
Constraint : 제약조건
- 데이터에 대한 규칙
- ex) 학번은 겹치면 안된다, 지도교수는 최소 한명 이상이어야 한다
Relational Model
- 데이터를 row 와 col 로 이루어진 테이블로 표현한 모델을 relational model 이라 부른다 (관계형 모델)
- Relation → table 을 나타내는 표현
- 두 테이블 사이의 관계는 FK-PK 관계로 표현된다
- 모델링을 할때는 relational model 이 아닌 다른, (한눈에 보기 쉬운) 모델을 사용한다
Entity-Relationship 모델
- 테이블 형태로 표현하지 않는 모델
- 개체와 관계를 중심으로 모델링을 한다
- 엔티티 사이의 관계는 선으로 표시한다

- 관계가 몇대 몇인지, 관계에서 해당 엔티티의 participation 등을 표시한다
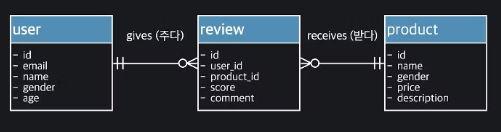
데이터 모델 스펙트럼
- conceptual model : 엔티티와 연결 관계만을 나타낸다
- 대략적인 구조 파악에 사용
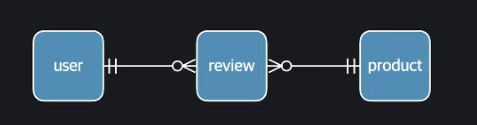
- Logical Model : conceptual + attribute
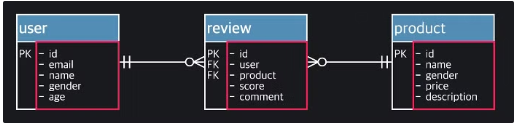
- Physical Model : 자세한 정보가 담긴 모델

좋은 데이터베이스
- 같은 데이터가 여러곳에 저장되어있거나, null 이 많거나, 연산 실행이 너무 오래 걸리거나, 원하는 정보를 찾을 수 없거나, 틀린 데이터를 저장하고 있는 데이터 베이스는 나쁜 데이터베이스이다
- 중복 이 없고, 틀린 데이터가 없고, 빠르고 정확하게 데이터를 다룰 수 있다면 좋은 데이터베이스이다
- 데이터 모델링을 어떻게 했는가에 따라, 데이터베이스가 좋을 수도 나쁠 수도 있다
- 아래의 테이블은 여러 주소를 가진 사람의 row를 여러번 중복하여 저장하고 있다
- 데이터 무결성을 유지하기도 어렵다
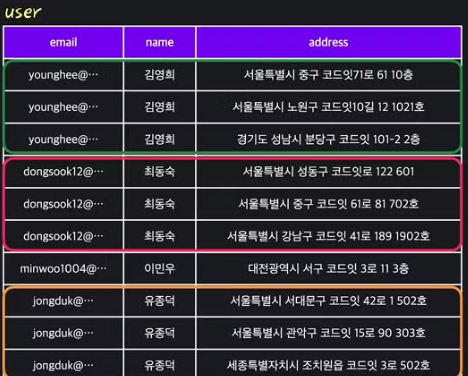
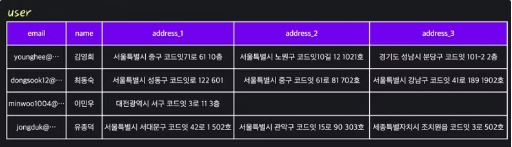
- 첫번째 보단 나은 예시이지만 여전히 문제가 생긴다
- ex) address 가 생길때 마다 컬럼이 늘어나야 한다, NULL 값이 많이 발생한다
- 다음은 잘 설계된 테이블의 예시중 하나이다
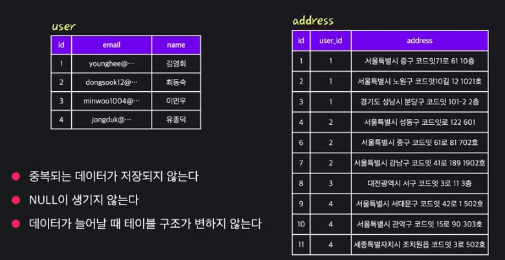
논리적 모델링
비즈니스 룰
- 특정 조직이 운영되기 위해 따라야 하는 정책, 절차, 원칙
- 서비스를 설계한 사람들이 정한 규칙
- 데이터 모델링의 핵심 기반
## 예시 business rule
- 유저는 상품을 주문할 수 있다
- 동일한 주문 내역은 한 번의 배달로, 3일 안에 유저가 지정한 배송지에
전달되어야 한다. 만약 그렇지 못할 시, 유저에게 최대한 빨리 알려줘야 한다
- 유저는 상품에 대한 평가를 할 수 있다: 두 종류의 데이터
-> 자연수인 별점, 200자 이내 글
Entity Attribute Relationship 후보 찾기
- 모든 명사는 entity 후보이다
- 모든 동사는 relationship 후보이다
- 하나의 값으로 표현할 수 있는 명사는 attribute 후보이다
- 유저는 상품을 주문할 수 있다
- Entity 후보 : 유저, 상품
- relationship 후보 : 주문
- 유저는 상품에 대한 평가를 할 수 있다: 두 종류의 데이터-> 자연수 별점, 200자 이내 글
- entity : 유저, 상품, 평가
- relationship : 주다
- attribute : 별점, 글
<aside> 💡
attribute 와 relationship들의 특성에 따라 모델링이 바뀔 수 있다
</aside>
여러 값을 갖는 attribute
- Entity 내에 똑같은 종류의 여러 attribute 를 저장해야 하는 경우가 있다
- 예를 들어, 한 유저가 여러 주소를 가질 수 있다
- address 컬럼을 여러개 만든다면, 많은 null 등의 좋지 못한 모델링이다
- address 테이블과 user 테이블을 따로 만들어, address 는 user id 를 FK 로 갖게 만들면 null 문제, 컬럼을 늘려야 하는 문제가 해결된다
Cardinality
- Entity A 와 Entity B 사이의 관계대응수이다
- 즉, A 하나가 B 몇개와 연결되는지, B 하나가 A의 몇개와 연결되는지
1 : 1 관계
- 하나의 A 에 대해 B도 하나, 하나의 B에 대해 A도 하나
1 : N 관계
- 하나의 A 에 대해 여러개의 B가 있을 수 있다. 여러개의 B 에 대해 하나의 A 만 있을 수 있다
N : M 관계
- 하나의 A 에 대해 여러 B, 하나의 B에 대해 여러 A 가 있을 수 있다
ERM & Cardinality
- Crow’s Foot Notation
- Relationship 은 선으로, Cardinality 는 선의 양끝에 표기를 하여 나타낸다

한개의 entity 가 연결되어야 하는 최소도 중요하다
ex) 하나의 user 는 comment 와 연결되지 않아도 되지만, comment 는 반드시 하나의 user 와 연결되어야 한다

N : M 모델링시, 연결 테이블을 사용한다 (Junction Table)
ex) user, product, 찜하기 관계를 표현하면,
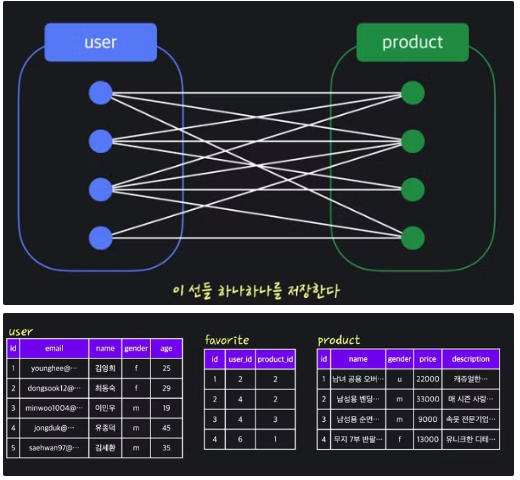
DB 이상현상
- 삽입이상: 새로운 데이터를 자연스럽게 저장할 수 없는 경우
- 업데이트 이상 : 데이터를 업데이트를 하였을때, 정확성을 지키기 어려운 경우
- 삭제이상 : 원하는 데이터만 삭제할 수 없는경우
정규화
NORMALIZATION
→ table 이 잘 만들어 졌는가를 평가 및 수정해나가는 과정
→ 정규형에 맞도록
함수종속성
- Functional Dependency
- x에 따라 y가 변화한다면, y는 x에 함수 종속성이 있다고 한다

Candidate Key
- 하나의 fow 를 특정지을 수 있는 attribute 들의 집합
- 아래의 경우, user id 와 product id 를 알면, 어떤 review 를 가르키는지 알 수 있다. 즉, userid, productid 혹은 id가 candidate key 이다

1NF
- 모든 로우의 모든 컬럼 값들이 나눌 수 없는 단일 값이어야 한다
- 컬럼을 늘리는 방법은 1NF를 지킨다고 볼 수 없다
- 위반되는 경우
- 한 컬럼에 같은 종류의 값을 여러개 저장
- 한 컬럼에 서로 다른 종류의 값을 저장
2NF
- 1NF 에 부합해야 한다
- table 의 candidate key 의 일부분에 대해서만 함수 종속성이 있는 non-prime attribute가 없어야 한다
- 아래 경우, uid, product id 로 하나의 row 를 특정지을 수 있다
- 하지만, 이 경우, age 는 user_id 에 대해서, price 는 product_id 에 대해서 함수 종속성이 있다 (즉 2nf 불만족)

3NF
- 2NF 에 부합해야 한다
- 테이블 안에 있는 모든 attribute 들은 오직 pk 에 대해서만 함수 종속성이 있어야 한다
물리적 모델링 범위
- 물리적 모델링이란 실제로 만들 DB에 가장 가깝게 데이터 보델을 만드는 과정
- 어떤 DBMS, 보안, 마스터권한, 등
네이밍
- 네이밍 규칙은 따로 정해져 있지 않다
- 조직의 규칙에 잘 따르면 된다
- 테이블 이름에 복수 단어를 사용
- 컬럼은 단수 사용
- 대문자 / 띄어쓰기 어떻게 처리할 지
- 띄어쓰기 : _, CamalCase, 등등
- 줄임말 정하기
- ex) Social Security Number → SSN
데이터 타입
- 각 컬럼이 어떤 데이터를 저장하는지에 대한 내용
- DB의 가장 기본적인 제약 사항
- 데이터의 정확성을 어느정도 까지는 지킬 수 있다
- TEXT 타입으로 모두 저장하게 되면 → 다양한 연산 혹은 함수 사용 불가능
- 알맞은 데이터 타입을 정하지 않으면 데이터베이스의 활용도가 떨어진다
- DB 용량을 최적화 할 수 있다
- 데이터의 제약조건
- ex) 성별 컬럼에는 f 혹은 m
- 이메일 컬럼에는 항상 @ 가 들어가야 한다
선형 vs 이진탐색
-
- 데이터를 찾는데는 두가지 방법이 있다 : 선형탐색, 이진탐색
- 정렬되지 않은 배열에서 특정 데이터를 찾는경우 : 선형탐색
- 정렬된 배열에서 특정 데이터를 찾는 경우 : 이진탐색
- 선형탐색 : O(n)
- 이진탐색 : O(log n)
- 인덱스 → 데이터 조회 속도를 높이기 위한 자료구조
- 특정 단어나 필요한 내용이 있는 페이지를 어떻게 찾을까
- 선형탐색으로 찾거나, 더이상 찾을 row가 없을때 까지 → 너무 오래걸린다
- index 는 특정 내용이 몇 페이지에 있는지를 기록해 둔 페이지
- 이 페이지는 정렬되어있다 → 이진탐색을 사용할 수 있다
- clustered index vs non-clustered index
- clustered : 테이블 자체를 특정 순서로 저장하는 인덱스
- 조회속도가 굉장히 빠르다
- 하나밖에 만들지 못한다 → 특정 기준으로 정렬되야하기 때문
- non-clustered: 테이블은 놔두고 다른곳에 저장
- 다음은 이메일 컬럼에 대한 non clustered index 이다
- clustered : 테이블 자체를 특정 순서로 저장하는 인덱스

- composite index
- 여러 컬럼에 대한 index
- 예를 들어, 브랜드, 종류, 색깔에 대한 조건으로 자주 검색한다면, 이 세 가지 컬럼에 대한 인덱스를 만들면 조회 성능이 향상된
- 단일 인덱스의 한계: 각각의 컬럼에 대해 따로 인덱스를 만들 경우, 하나의 인덱스로 특정 조건(예: 브랜드)을 찾고 나머지 조건(예: 종류)에 대해서는 선형 탐색을 해야 하는 상황이 발생할 수 있다. 따라서 여러 개의 조건을 동시에 사용하여 검색할 때는 단일 인덱스로는 최적의 성능을 내기 어렵다.
- 복합 인덱스의 이점: 복합 인덱스를 사용하면 각 컬럼에 대해 이진 탐색을 연속적으로 수행할 수 있어, 데이터를 더욱 빠르게 조회할 수 있다. 예를 들어, 브랜드로 먼저 이진 탐색하고, 그 안에서 종류, 색깔을 다시 이진 탐색할 수 있다.
- Index 단점
- 모든 컬럼과 조합에 대해 인덱스를 추가하지는 않는다
- 용량문제
- 데이터에 대한 수정이 있을 때, 바꿔야 하는 내용이 많아진다
- 인덱스 기본 원칙
- 모든 pk 에 대해 만든다
- 모든 fk 에 대해 만든다
- 특정 조회 쿼리가 너무 느려질 경우, 조회에 사용되는 컬럼들에 대해 인덱스를 만든다
- 인덱스 생성 sql
CREATE CLUSTERED INDEX index_name ON table_name (column_name)
CREATE INDEX index_name ON table_name (column_name)
CREATE INDEX index_name ON table_name (column_name_1, column_2, ...)
SHOW INDEX FROM table_name;
DROP INDEX index_name ON table_name;