
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- factory
- Spring
- java
- Dependency Injection
- 일급 컬렉션
- Google OAuth
- builder
- middleware
- Volatile
- spring security
- OAuth 2.0
- nestjs
- lombok
- synchronized
- 일급 객체
- Today
- Total
HJW's IT Blog
JVM 은 어떻게 동작하는가 본문
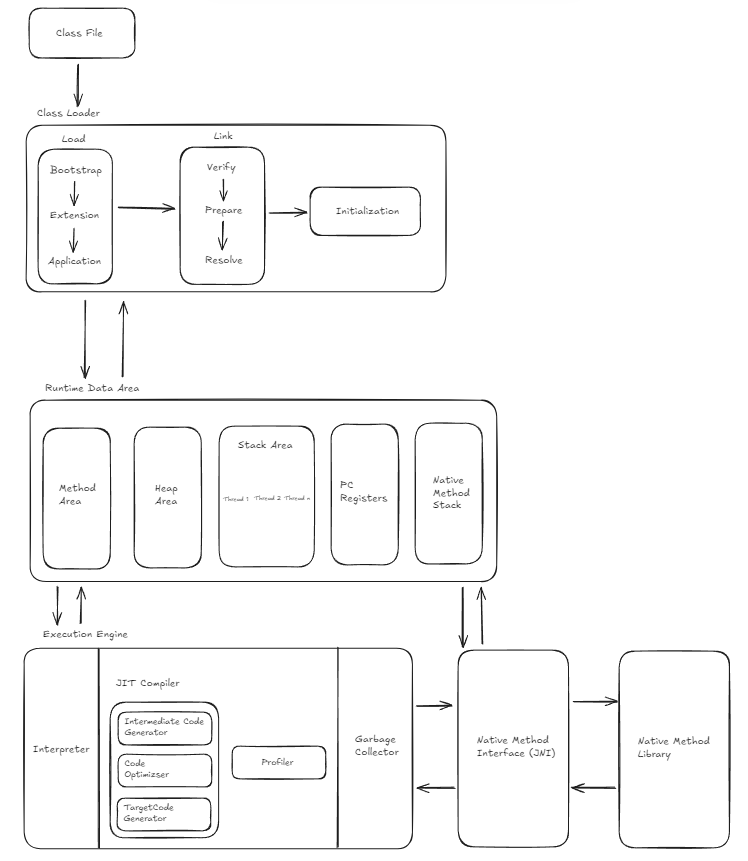
1. Class Loader System
JVM 의 `Class Loader` 는 Java 프로그램 실행 시 필요한 클래스를 **동적** 으로 로드하는 역할을 한다. 즉, 프로그램 실행시 모든 클래스를 한번에 메모리에 올리는 것이 아닌, 특정 클래스가 필요할 때 해당 클래스 파일을 로드하고 초기화 시키기에 메모리 낭비를 막을 수 있다.
`Class Loader` 는 기본적으로 loading - linking - initialization 의 과정을 거친다. 자세히 알아보자
1.1 Loading
이 과정에서, 클래스 파일이 로드된다. 클래스 로더는 특정 클래스의 이름을 기반으로 클래스를 찾고, JVM 메모리에 읽어들인다. 이 과정속, 클래스 로더는 주요 3가지 로더를 거치는데, 이들은 계층형 구조를 띄며, 상위 로더가 실패했을 경우 하위 로더가 동작하는 방식이다. 각 로더에 대해 알아보자.
1.1.1 Bootstrap Class Loader
`Bootstarp Class Loader` 는 가장 기본적인 class loader 로 최상위 계층 loader 이다. JVM 이 시작할때 가장 먼저 동작하여 시스템에 필요한 가장 기본적인 클래스들을 로드한다. 특징은 다음과 같다
**JDK 핵심 클래스 로드** : `java.lang`, `java.util` 등 핵심적인 Java 클래스 라이브러리를 로드하는데, `$JAVA_HOME/lib` 디렉토리에서 로드된다.
**최상위 클래스 로더** : 다른 로더의 영향을 받지 않는다
**커스터마이징 불가능** : 사용자가 임의로 수정하거나 대체할 수 없다
1.1.2 Extension Class Loader
`Bootstrap Class Loader` 의 다음 계층으로, Java 의 확장 기능을 지원하는 클래스 들을 로드한다. 이때 확장 클래스란 JDK 에 포함되진 않지만, JVM 이 추가적인 기능을 제공하기 위해 사용하는 클래스를 말한다. `$JAVA_HOME/lib/ext` 에 정의되어 있는 클래스 들을 로드한다.
1.1.3 Application Class Loader
`Application Class Loader` 는 loader 중 가장 하위 계층의 로더이며, 여기서 사용자가 작성한 어플레케이션 코드와 라이브러리들이 로드된다. 이 로더는 어플리케이션 코드오 ㅏ외부 라이브러리를 classpath 에 따라 로드하며, 커스터마이징과 동적 로딩을 허용한다.
1.2 Linking
클래스 로더가 메모리에 클래스를 로드한 뒤엔, 이 클래스가 실행 가능하도록 준비해야 한다. 이 과정은 3 단계로 나뉜다.
1.2.1 Verification
JVM 이 로드된 클래스 파일이 JVM 의 명세를 준수하는지 확인하는 과정이다. Class Loader System 에 들어오기 전, Java 클래스 파일들은 Java compiler 에 의해 바이트 코드로 변환이 된다. 이 단계에선, 바이트코드가 JVM 이 정의한 규칙에 맞는지 검사한다.
- 파일 형식 검증 : 클래스 파일이 올바른 구조로 작성되었는지
- 구조 검증 : 클래스 내부 구성 요소 (메서드, 필드, 상속관계 등) 이 JVM의 명세를 준수하는지 검사
- 타입 검증
- 제어 흐름 검증 : 바이트 코드가 논리적으로 유효한 실행 경로를 가지는지 확인한다.
1.2.2 Preparation
이 단계에서, JVM 은 static 필드와 클래스 레이아웃을 메모리에 할당하고, 초기값으로 설정하는 과정이다. 즉, 클래스의 실행과 관련된 구조가 메모리에 준비된다.
- static 필드 메모리 할당 : 기본값으로 초기화 되는데, primitive type 의 경우 0, 0.0 등, reference type 은 null 로 초기화 된다
- Constant Pool 초기화 : 클래스 파일에 포함된 상수 풀을 JVM 내부에서 사용 가능한 형태로 변환한다
- 상속 관계 설정 : 클래스가 구현해야 하는 상속 계층을 확인하고 저장한다
1.2.3 Resolution
이 단계에선, 클래스 내부에서 사용되는 심볼릭 참조를 실제 direct reference 로 변환하는 과정이다. 심볼릭 참조는 여러 데이터를 추상적인 형태로 표현한 것인데, 이 단계에서 JVM 이 이해할 수 있는 메모리 주소로 변환해야 한다.
- 클래스 참조 해결 : 클래스가 참조하는 다른 클래스를 메모리에 로드
- 필드 참조 해결 : 바이트 코드에서 사용되는 심볼릭 필드 참조를 실제 메모리 주소로 변환한다
- 메서드 참조 해결 : 메서드 호출과 관련된 심볼릭 참조를 실제 메서드의 메모리 주소로 변환한다.
이 단계는 runtime 에 수행될 수도 있다. 이를 통해 동적 로딩이 가능해진다.
1.3 Initialization
이 단계는 클래스가 정적으로 정의된 구성 요소를 실행하여 해당 클래스가 실행 가능한 상태가 되도록 만드는 단계이다. 이 단계는 클래스가 실제로 사용되기 전에 실행된다.
클래스의 정적 멤버와 정적 초기화 블록이 실행되며, 이제 최종적으로 실행 가능한 상태가 된다. JVM 은 초기화를 뒤로 미루다, 다음과 같은 상황에 실행시킨다
- 클래스의 정적 메서드가 처음 호출될때
- 정적 변수가 처음 참조될때
- 인스턴스가 처음 생성될 때
각 클래스는 초기화 **상태**를 가진다.
- Not Initialized
- Being Initialized
- Fully Initialized
*왜 상태가 필요할까?*
JVM 이 순환 참조를 처리해야 하기 때문이다. 만약 Class A 가 초기화 되는 중인데, Class B가 A 를 참조해야 하는 상황에서 충돌이 일어나지 않게 하기 위한 장치인 것이다. JVM 은 다음 절차를 밟아 순차적 초기화를 보장한다.
- Class A 가 초기화 중이라면, Being Initialized 상태를 준다. Class B 가 해당 클래스를 참조하려 하면, 참조 요청 자체를 Pending 상태로 보류한다.
- Class A 의 초기화가 완료되면, Pending 상태이던 Class B의 초기화를 이어서 진행한다.
- JVM 은 한번에 하나의 클래스만 초기화 하도록 설계되어 초기화 중인 클래스의 작업을 중복으로 실행하지 않는다.
2. Runtime Data Area
Runtime Data Area 는 프로그램 실행 중 JVM 이 사용하는 메모리 구조이다. 크게 Thread-Specific Area 와 Shared Area 로 나뉜다. 각 영역은 Java 프로그램 실행의 과정을 지원하며, 각 영역별로 특정 예외가 발생할 수 있다.
2.1 Shared Area
2.1.1 Heap
JVM의 heap 영역은 런타임에 객체, 배열들이 생성되는 공간이다. 즉, 동적 메모리 할당 이 가능하며, 모든 스레드에서 공유되는 영역이다. 이 영역인 차후 설명한 Garbage Collection의 주요 대상이 되는 공간이다. Heap 영역은 또한 세부적으로 나뉘는데, 다음과 같다.
2.1.1.1 Young Generation
- Eden Space : 새로 생성된 객체가 처음 할당되는 공간. 이때 eden space 가 가득 찰 경우, Minor GC 가 발생하여 사용되지 않는 객체들을 정리한다.
- Survivor Space : Eden Space 에서 살아남은 객체들이 이동하는 곳으로, 이곳에선 객체들은 S1, S0 을 오가며 생존 기간이 길어질 경우, Old Generation 으로 이동한다. 이 과정은 Promotion 혹은 Tenuring 이라 한다.
2.1.1.2 Old Generation
- Young Generation 에서 살아남아 오래된 객체들이 이동하는 영역이다
- Young Generation 에 비해 크기가 크며, GC 가 덜 빈번하게 일어난다 (Major GC)
2.1.1.3 동작과정
- Eden Space 에 객체 생성 -> 가득차면 minor GC 실행
- Survivor Space 이동 -> 객체들이 S1, S0 를 오가며 age 가 늘어남
- Survivor Space 에서 일정 시간 지난 객체는 Old Generation 으로 넘어감
2.1.1.4 JAVA 8 전후
JAVA 8 이전에는 Permanent Generation 이라는 영역이 있었으나, OutOfMemorryError 가 빈번하게 발생하여 변경되었다.
이제 Heap Memory 는 아니지만 동적으로 확장 가능한 Metaspace 가 있으며 Native Memory에 존재한다.
2.1.2 Method Area
이 영역은 JVM 이 시작될때 생성되며, Class 와 Interface 의 구조적 정보를 저장하는 공간이다. Heap Memory 와 마찬가지로, 모든 thread 가 공유하는 영역이다. [[1. Class Loader System|Class Loader]] 가 클래스 파일을 로드하면, 그 정보가 파싱되어 이 영역에 저장된다.
이 영역은 다음 정보를 저장한다.
- 클래스 메타데이터 : 클래스 이름, 부모 클래스, 메서드, 필드
- Byte Code : 클래스 파일의 byte code 가 여기에 로드되어 실행 준비가 된다
- Runtime Constant Pool : literal, number constant, etc
이 영역은 JVM Spec 상 논리적인 영역으로 정의되어 있으며, 여기에 저장되는 데이터도 GC 의 대상이 될 수 있다.
Metaspace
Java 8 이전에는 클래스 메타데이터와 런타임 상수 풀이 PermGen(Permanent Generation) 이라는 영역에 저장되었다. PermGen은 Heap 영역의 일부로, 크기가 고정되어 있어 자주 OutOfMemoryError를 유발했다.
JAVA 8 부턴, 이를 Metaspace 가 대체하기 시작했다. PermGen과 달리 Metaspace는 Heap 외부의 Native Memory에 위치한다.PermGen 처럼 고정된 크기가 아니며, 동적으로 확장될 수 있다(OS 가 허용하는 메모리 한도에 따라 크기가 변화) .
- [!] Method Area 는 논리적 설명이며, PermGen 과 Metaspace 은 Method area 의 물리적 구현이다
2.2 Thread-Specific Areas
2.2.1 Stack Area
JVM 의 Stack 영역은, 각 스레드마다 독립적으로 존재한다. 해당 영역엔, 메서드 호출과 관련된 데이터들이 저장되며, LIFO 구조를 가진다.
메서드가 호출되면, 새로운 스택 프레임(Stack Frame)이 생성되고, 메서드 실행이 완료되면 해당 프레임이 제거되는 방식으로 동작한다.
Stack 영역은 또 여러 Stack Frame 으로 구성되는데, 각 Frame 의 구성은 다음과 같다
- Local Variables -> 메서드의 매개변수, 지역변수가 저장된다. 메서드 종료시 제거된다.
- Operand Stack -> JVM 명령어가 실행되는 동안 임시 데이터가 저장된다.
- iadd, iload, istore 등의 stack 연산을 하는데, 예를 들어 iadd 의 경우, 피연산자 스텍에서 데이터를 꺼내 연산하고 다시 결과를 push 하게 된다.
- Frame Data -> return addr, exception handling 등의 정보가 저장된다.
JVM 에서 Stack area 의 크기는 고정되거나, 동적으로 확장될 수 있는데, 동적 확장이 허용되는 경우, 확장에 실패시 OutOfMemoryError 가 발생한다. 또한, Stack 이 가득차게 되면 StackOverflowError 가 발생하게 된다.
- [!] 이전에 언급했듯, Stack 은 각 스레드에 독립적으로 할당되기 때문에, 하나의 스레드에서 발생한 에러는 다른 스레드에 영향을 미치지 않는다.
Stack Trace -> 프로그램 실행 중 예외 발생시, 현재 stack 의 상태를 캡처하여 예외 위치와 메서드 호출의 순서를 기록한다.
2.2.2 PC Register
Stack Area 와 마찬가지로, 각 스레드마다 할당되는 메모리 영역이다. 이 영역에는 , 현재 실행중인 JVM 명령어의 주소 가 저장된다.
만약 스레드의 [[Context Switching]] 이 일어날 경우, 현재 스레드의 PC Register 상태를 저장하고, 다음 실행될 스레드의 PC Register 상태를 복원한다.
동작 방식
- JVM 명령 실행 : 현재 PC Register 가 가르키는 주소의 JVM 명령어를 수행
- 명령 완료시, 다음 명령어의 주소로 update
- 보통 순차 실행
- 분기 실행 -> 분기 조건에 따라 특정 주소
- 메서드 호출 및 반환
- [!] 네이티브 메서드의 경우, PC Register 는 추적하지 않는다
2.2.3 Native Method Stack
Native Method 란?
JVM 에서 Java 코드가 아닌 네이티브 코드로 작성된 메서드를 의미한다.
Native Method Stack 은 이러한 Native method 를 실행하기 위해 사용하는 메모리 영역이다. 이 영역 또한 스레드 별로 독립적인 영역을 할당받게 된다.
JNI(Java Native Interface) 를 통해 호출되는 메서드를 지원하며, 이 영역에 매개변수, 지역변수, return value, 등이 저장된다.
3. Execution Engine
Execution Engine 은 Byte 코드로 컴파일된 java 코드를 실제로 실행하는 역할을 담당한다.
3.1 구성 요소
3.1.1 Interpreter
Interpreter 는 .class 파일에서 로드된 바이트 코드를 한줄씩 읽고 실행한다. 해석된 바이트 코드의 명령어에 따라 실제 연산을 수행하며, 해당 명령이 끝날 시 다음 명령어로 이동한다. 여기서 중요한 점은, 바이트 코드를 한줄씩 읽어 즉시 실행한다는 점이다. 즉, 컴파일 단계가 필요 없다. 이러한 이점은, 컴파일이 필요 없기에, 동적으로 유연하게 실행할 수 있다는 뜻이다.
Interpreter 는 바이트 코드를 실행하기 때문에, 자바의 Write Once Run Anywhere 의 철학을 지원하게 된다. 즉, 자바의 플랫폼 독립성을 유지하는데 도움이 된다.
3.1.2 JIT (Just In Time) Compiler
Interpreter 는 Java byte code 를 컴파일 없이 한줄 씩 읽어 실행한다고 했다. 그렇다면 이 컴파일러는 어디에 사용되는 것일까?
JIT Compiler 는 runtime 에 byte code 를 native code (기계어) 로 변환하는 역할을 한다. Jit Compiler 없이 Interpreter 만을 사용한다면, 플렛폼 독립성을 제공하는 대신 느리다는 단점이 있었다.
JIT Compiler 동작 방식
- 프로그램 실행 초기에, JVM 은 interpreter 를 사용해 바이트 코드를 실행
- JIT Compiler 는 실행 중인 코드의 실행 빈도를 모니터링하여, 자주 실행되는 코드 블록을 hotspot 으로 지정
- hotspot 이라 판단된 코드를 native code 로 컴파일
- 이후 해당 코드 블록을 실행할 경우, interpreter 를 사용하지 않고, 컴파일 된 native code 를 실행한다
- 필요에 따라 JIT 컴파일러는 이미 컴파일 된 코드를 다시 최적화 할 수 있다.
Jit Compiler 종류
- C1 컴파일러 : 간단하게 빠른 컴파일에 사용된다. 초기 실행 속도는 빠르나 성능이 떨어진다
- C2 컴파일러 : 고급 최적화 기법을 사용하여, 코드 실행 성능을 극대화 하는데 초점이 맞추어져 있다. 컴파일 시간이 오래 걸리지만, 컴파일된 코드의 성능은 C1 보다 뛰어나다
3.1.3 Garbage Collector
Garbage Collector 는 Java 프로그램이 실행되는 동안 더이상 사용하지 않는 객체를 자동으로 찾아 메모리에서 제거하는 자동 메모리 관리 시스템 이다.
C/C++ 에선 malloc() 으로 메모리를 할당하고, free() 로 해제해야 한다. 하지만 Java 의 GC 는 이러한 과정을 자동으로 처리한다. GC 는 그렇다면 어떻게 어떤 객체가 더이상 사용되지 않는지 판단할까?
Reachability
- GC 는 특정 객체가 GC Root 로 부터 참조 체인(Graph) 를 통해 도달할 수 있는지 여부를 가지고 reachable object, unreachable object로 나눈다.
- GC Root 란 참조 탐색이 시작되는 기준점들을 말한다 (Stack Frame 의 지역변수, 메서드 영역의 정적 변수 등)
- Unreachable Object 의 경우 Garbage 로 간주하여 메모리에서 제거하게 된다.
GC 는 주로 Heap Memory 에서 동작한다. Young Generation 에선 minor GC 가 상대적으로 빈번하게 동작하며, Old Generation 에선 Major GC 가 동작하는데, Major GC 는 오버해드가 크다.
4. Native Method Interface
Java 코드에서 Native 코드를 호출할 수 있도록 인터페이스를 제공한다.
5. Native Method Libraries
플랫폼 의존적인 Native 코드가 저장된 라이브러리이다.
6. Garbage Collection 종류
6.1 Serial GC
단일 스레드로 동작하며, 모든 young generation, old generation 을 하나의 스레드가 처리한다. 이 구조는 단순하며, CPU 코어가 하나인 작은 어플리케이션에 적합하다.
Stop-The-World 시간이 가장 길다.
Mark-Sweep-Compact 를 사용한다
6.2 Parallel GC
GC 작업을 병렬 스레드로 수행하여 처리 속도를 높인다. Throughput 을 극대화 하는데에 중점을 두며, 대용량 데이터를 처리하는 배치 작업 및 서버 환경에 적합하다.
Java 8 의 기본 GC 이다.
Mark-Summary-Compact 를 사용한다.
6.3 CMS : Concurrent Mark-Sweep GC
멀티 스레드 방식으로 동작하며, Stop-The-World 시간을 최대한 줄이기 위해 고안되었다. 단, 다른 GC 대비 CPU 사용량이 높으며, memory-fragmentation 문제가 있다.
JAVA 14에선 사용이 중지되었다.
6.4 G1 GC
CMS GC 를 대체하기 위해 탄생했다. JAVA 9 이후의 디폴트 GC로, young, old 를 구분하지 않고 Region 이라는 영역으로 분할하여 동작한다.
우선순위에 따라 가장 많이 회수할 수 있는 영역부터 수집한다.
compaction 도 수행 가능하며, memory fragmentation 이 적다.
6.5 Z Garbage Collector
매우 짧은 STW 를 목표로 설계되었다. 10ms 이하의 중단 시간을 보장하는데, 객체의 이동을 위해 Load Barrier 를 사용하며, 높은 메모리, CPU 오버헤드가 발생한다. JAVA 11 이상만 지원한다
6.6 Shenandoah GC
redhat 에서 개발한 GC 로, 기존 CMS 가 가진 단편화, G1이 가진 pause 이슈를 해결하였다.
7. JMM
Java Memory Model (JMM) 이란 Java 멀티스레드 환경에서 메모리 접근과 관련된 규칙을 정의한 메모리 관점의 명세이다. JMM 은 JVM 이 멀티 스레드 환경에서 공유 메모리를 어떻게 다루고 스레드간 visibility 를 보장할지에 대한 규칙을 다룬다.
7.1 스레드간 가시성
각 스레드는 자신만의 작업 공간에서 변수를 읽고 수정한다. 이때, 여러 스레드가 동시에 공유 변수에 접근하는 경우, 한 스레드가 변경한 값이 다른 스레드에 언제, 어떻게 보이는지를 정의한다.
JMM 은 volatile 혹은 synchronized 블록을 통해 스레드간 변수값이 올바르게 공유될 수 있도록 한다7.2 명령 재배열 방지
컴파일러, CPU 는 코드의 실행 성능증대를 위해 명령어의 순서를 재배열 할 수 있는데, 이러한 최적화 과정이 멀티스레드 환경에서 예상치 못한 결과를 불러올 수 있다. 그렇기 때문에, JMM 은 volatile, synchronized 가 적용된 블록의 재배열을 허용하지 않는다.
7.3 원자성 보장
synchronized , volatile 을 통해 특정 연산이 중간에 다른 스레드에 의해 방해받지 않음을 보장한다.
7.4 메모리 접근 순서
메인 메모리는 모든 스레드가 공유하는 데이터 영역인 반면, 스레드 작업 메모리는, 각 스레드만의 작업 공간이다. 여기선, 각 스레드가 메인 메모리에서 읽어온 값을 캐싱하고, 수정된 값도 메인 메모리에 다시 쓰는 작업을 한다.
JMM 은 각 스레드의 메모리 접근 순서가 다른 스레드에게 어떻게 보여지는지를 정의한다. 즉, 프로그램 실행 순서와 메모리 접근 순서가 반드시 일치하지 않을 수 있음을 유추할 수 있는데, JMM 은 happens-before 라는 개념을 통해 이러한 메모리 접근 순서를 정의한다.
- 프로그램 순서 규칙 : 한 스레드 내에서 프로그램 순서대로 실행되는 접근은 happens-before 관계를 가진다
- 모니터 락 규칙 :
synchronized블록 진입 전의 메모리 접근은synchronized내부의 메모리 접근보다 happens-before 관계를 가진다 - volatile 변수 규칙 :
volatile변수에 대한 쓰기 작업은 그 변수에 대한 읽기 작업보다 happens-before 관계를 가진다 - 스레드 시작, 종료 규칙 : 스레드 시작 이전의 작업은 내부의 작업보다 happens-before 관계를 가지며, 스레드의 모든 작업이 완료된 이후의 작업은 스레드의 종료보다 happens-before 관계를 가진다.
이러한 규칙은 멀티스레드 환경에서 race condition, 가시성 문제를 방지할 수 있다.
'JAVA' 카테고리의 다른 글
| DTO ↔ 엔티티 변환, MapStruct로 자동화하기 (0) | 2025.02.18 |
|---|---|
| Spring 없이 의존성 관리와 팩토리 패턴 구현하기 (0) | 2025.01.24 |
| JAVA Volatile 키워드와 멀티쓰레드 (0) | 2025.01.13 |
| [JAVA] Collections Framework (Linked List, Stack, Queue, Set) (1) | 2024.10.13 |
| [JAVA] Collections Framework 1 (Generic, ArrayList) (1) | 2024.10.13 |
