
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- synchronized
- lombok
- OAuth 2.0
- factory
- nestjs
- spring security
- Google OAuth
- Dependency Injection
- 일급 객체
- Spring
- middleware
- java
- Volatile
- builder
- 일급 컬렉션
- Today
- Total
HJW's IT Blog
Batch Fetching + Pagination으로 N + 1 해결하기 본문
0. N + 1 이란
Spring Data JPA 에서 연관관계가 있는 엔티티를 조회할 때, Lazy Loading 을 활용하여, 실제 데이터가 필요한 시점까지 연관 엔티티의 조회를 미룰 수 있다.
이는 양날의 검과 같다. 최적화를 하는 동시에 성능에 지대한 영향을 미칠 수 있다. 단편적인 예시가 바로 N + 1 문제이다.
한번의 부모 엔티티 조회 후, 각 자식 엔티티를 개별적으로 조회하는 비효율적인 쿼리 실행 문제를 두고 부르는 말이다.
@Entity
public class User {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Order> orders;
}
@Entity
public class Order {
@Id @GeneratedValue
private Long id;
private String product;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
}
이와 같은 User 와 Order 관계가 있다고 가정하자. 그리고 다음과 같은 상황을 분석해 보자
List<User> users = userRepository.findAll();
for (User user : users) {
List<Order> orders = user.getOrders();
}
- 이때, User는 Order 를 Lazy Loading 으로 가져온다. 즉, 실제 필요 시점까지, 해당 필드는
PersistentBag가 차지하고 있다. 문제는 for문 내에서orders를 불러올 때 발생한다. 각 user 1명당 Order 를 조회하기 위한 쿼리가 1번씩 실행된다. - 즉 100 명의 User 에 대해 이런 쿼리를 날린다면 총
- 1 (userRepository.findAll()) + N (user.getOrders()) 의 쿼리, 즉 101개의 쿼리가 실행되게 된다.
N + 1 의 해결방법은 많다. FETCH JOIN, Entity Graph 등 다양한 방법으로 해결할 수 있다.
하지만, 위에서 언급한 FETCH JOIN 에는 치명적인 단점이 있다. 바로 페이징이 불가능 하다
0.1 왜 페이징이 불가능 할까?
다음과 같은 JPQL 을 실행한다고 가정하자.
SELECT u FROM User u JOIN FETCH u.orders- 이때, 한명의 User 는 여러개의 Order 를 가질 수 있다. 즉, User 가 여러 Order 를 가지게 되면, 중복된 User 데이터가 늘어나게 된다.
- 그렇다면 이 상태에서
setMaxResults(2)를 적용한다면, JPA 는 LIMIT 을 쿼리에 적용시켜야 한다. - 하지만, 이때 정확하게 2명의 User 만 가지고 오는 것은 불가능 하다 -> 중복 데이터가 포함되기 때문
- 예를 들어 한명의 User 가 5개의 Order 를 가지는 상황에서, User 데이터는 5번 반복된다.
0.2 그렇다면 페이징은 N + 1 을 감수할 수 밖에 없나?
다행히도, Batch Fetching 과 Pagination 을 활용하여 쿼리의 수를 최적화 할 수 있다. 이번 포스팅에서는 이 기법에 대해 알아보겠다.
1. @BatchSize 설정하기
기본적으로 @BatchSize 는 컬랙션 필드에 적용해야 한다. @OneToMany, @ManyToMany
@Entity
public class User{
@Id @GeneratedValue
private Long id;
private String name
@OneToMany(mappedBy = "user", fetch = fetchType.LAZY)
@BatchSize(size = 100)
private List<Order> orders = new ArrayList();
}
위와 같이 @BatchSize(size = 100) 을 적용하면 , 최대 100명의 User 의 Order 를 한번의 IN 쿼리를 활용하여 가져오게 된다.
2. Pagination 같이 적용하기
위의 @BatchSize() 만으로는 여전히 User 의 페이징을 처리할 수 없다. 이 문제를 해결하기 위해 Pagination 을 적용하여 User 를 먼저 조회한 후, Batch Fetching 을 활용해 Order 를 조회하는 방식을 사용한다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u.id FROM User u") // pagination 조건에 맞는 User ID만 먼저 조회
Page<Long> findUserIds(Pageable pageable);
@Query("SELECT u FROM User u WHERE u.id IN :userIds") // 조회된 UserId를 사용하여 USER list 불러오기
List<User> findUsersWithOrders(List<Long> userIds);
}@Service
@RequiredArgsConstructor
public class UserService{
private final UserRepository userRepository;
public List<User> getPagedUserWithOrders(int page, int size){
Page<Long> userIdsPage = userRepository.findUserIds(PageRequest.of(page, size));
List<Long> userIds = userIdsPage.getContent();
return userRepository.findUserWithOrders(userIds);
}
}
- 만약 Batch가 적용되지 않은 상황을 가정해 보자. 10명의 User 에 대한 조회 결과를 반환해야 한다면, (UserIds 조회) 1 + (각 User 마다 orders 조회) 10 = 11 번의 쿼리가 발생하게 된다.
- 하지만 pagination 과 batch size 가 적용 되었다면?
- findUserIds: 페이징된 User ID를 조회 (1번 쿼리).
- findUsersWithOrders: 해당 ID로 User를 조회 (1번 쿼리).
- orders 조회: @BatchSize에 의해 IN 쿼리로 한 번에 처리 (1번 쿼리).
- 총 3번의 쿼리로 해결할 수 있게 된다.
3. 테스트
@DataJpaTest
@Transactional
@Rollback(value = false)
public class BatchTest {
@Autowired private UserRepository userRepository;
@Autowired private OrderRepository orderRepository;
@PersistenceContext private EntityManager entityManager;
private static final int TOTAL_USERS = 200;
private static final int ORDERS_PER_USER = 10;
@BeforeEach
void setUp() {
// 대량 데이터 삽입
if (userRepository.count() == 0) {
List<User> users = new ArrayList<>();
for (int i = 0; i < TOTAL_USERS; i++) {
User user = new User();
user.setName("User " + i);
users.add(user);
}
userRepository.saveAll(users);
List<Order> orders = new ArrayList<>();
for (User user : userRepository.findAll()) {
for (int j = 0; j < ORDERS_PER_USER; j++) {
Order order = new Order();
order.setProduct("Product " + j);
order.setUser(user);
orders.add(order);
}
}
orderRepository.saveAll(orders);
}
entityManager.flush();
entityManager.clear();
}
@Test
void testPaginationWithBatchFetching(){
Page<Long> userIdsPage = userRepository.findUserIds(PageRequest.of(0,10));
List<Long> userIds = userIdsPage.getContent();
List<User> users = userRepository.findUsersWithOrders(userIds);
for(User user : users){
for(Order o : user.getOrders()){
o.getProduct();
}
}
}
}
@BatchSize() 없이
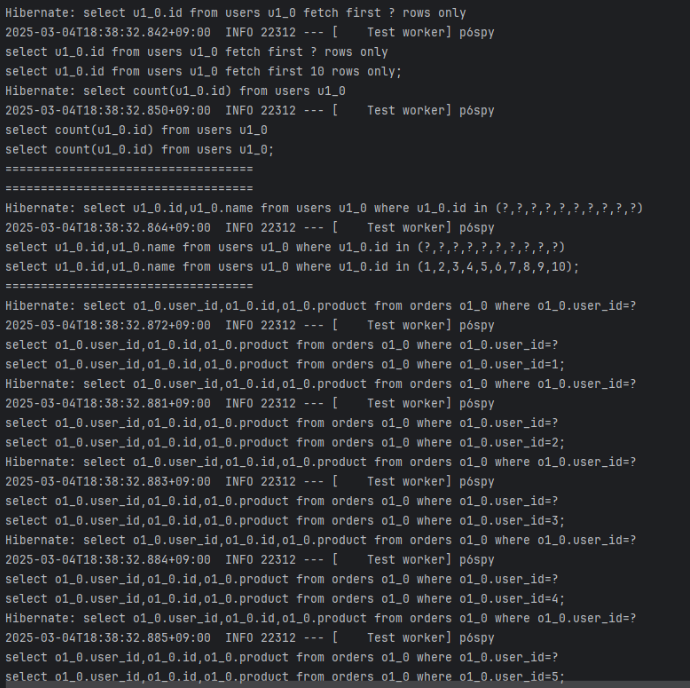
- 여러번의 쿼리가 나간다
- findUserIds: 1번
- findUsersWithOrders: 1번
- orders 조회: 10번 (각 User별 1번)
- 총 12번 쿼리 (N + 1 문제 발생)
@BatchSize(size = 5)

- 두번에 걸쳐 batch 를 처리한다
- findUserIds: 1번 (Pagination 쿼리가 총 2번 일어나지만 본 글에선 1개의 쿼리로 치부하겠다)
- findUsersWithOrders: 1번
- orders 조회: 2번 (10명을 5명씩 2번)
- 총 4번 쿼리
@BatchSize(size = 10)
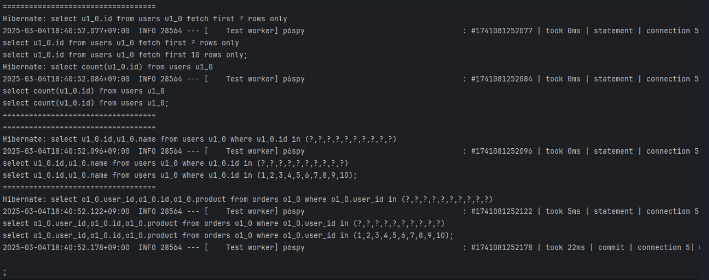
- 한번의 batch 에 전부 처리한다.
- findUserIds: 1번
- findUsersWithOrders: 1번
- orders 조회: 1번 (10명을 한 번에)
- 총 3번 쿼리
FETCH JOIN으로 테스트 해보기
Repository 의 코드를 다음과 같이 바꾼 후 실행시켜 보겠다.
@Query("SELECT u FROM User u JOIN FETCH u.order")
Page<User> findUsersWithOrders(Pageable pageable);

첫 WARN 로그를 분석해보자.
WARN 30136 --- [ Test worker] org.hibernate.orm.query : HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
이는 Hibernate 가 JOIN FETCH 를 활성화한 상태에서 firstResult 와 maxResult 를 설정했음을 의미한다.
그렇기에 이전 쿼리에서 볼 수 있었던 fetch firest ? rows only 쿼리가 찍히지 않는 것을 볼 수 있으며, 이 상태는, DB 에서 직접 페이징을 수행하지 않고, 메모리에 모두 올린 후 메모리에서 페이징을 징행하는 방식인 것이다.
4. findUsersWithOrders 에선 fetch join 을 사용해도 무방한가?
페이징을 할때, FETCH JOIN 을 사용하는것은 매우 위험하다는 것은 위에서 증명되었다. 그렇다면 페이징을 하는 메서드가 아닌 findUsersWithOrders 에선 fetch join 을 사용해도 될까?
즉, 다음 두 쿼리중 어떤 쿼리를 사용할지에 대한 고민이다.
@Query("SELECT u FROM User u WHERE u.id IN :userIds") // 조회된 UserId를 사용하여 USER list 불러오기
List<User> findUsersWithOrders(List<Long> userIds);
@Query("SELECT u FROM User u JOIN FETCH u.orders WHERE u.id IN :userIds") // 조회된 UserId를 사용하여 USER list 불러오기
List<User> findUsersWithOrders(List<Long> userIds);
위의 테스트 코드에서 각각의 쿼리를 사용했을 때 어떤 일이 벌어지는지 분석해보자.
Fetch Join
Page<Long> userIdsPage = userRepository.findUserIds(PageRequest.of(0, 10));쿼리가 우선 실행된다.- 데이터베이스에서 페이징 조건에 따라 UserID 10 개를 가져온다.
- userId 로 추출해 다시 repository 의
findUsersWithOrders()로 넘긴다. - 이때 다음과 같은 쿼리가 나간다
select
u1_0.id,u1_0.name,o1_0.user_id,o1_0.id,o1_0.product
from
users u1_0
join
orders o1_0
on u1_0.id=o1_0.user_id
where
u1_0.id in (1,2,3,4,5,6,7,8,9,10);- 이후, for(User user : users) 에서 각 user 의 order 정보를 조회할 때 나가는 쿼리는 없다
- 장점
- 쿼리 횟수를 최소화 할 수 있다
- Lazy Loading 을 방지하여 Order 정보를 즉시 사용할 수 있다
- 단점
- 중복 데이터가 발생한다 : User 정보가 Order 정보 개수 만큼 중복되어 로딩 (DISTINCT) 로 해결 가능
- 페이징 제약
- 데이터의 양이 많아지게 될 경우, 성능 저하가 심각하다
일반 쿼리(BatchSize 사용)
- 위와 동일하다,
findUsersWithOrders()에서 다른 쿼리가 나간다
select
u1_0.id,u1_0.name
from
users u1_0
where
u1_0.id in (1,2,3,4,5,6,7,8,9,10);- 즉, JOIN 없이 order 는 로드하지 않고 순수 user 에 대한 정보만 DB 에서 받아오는 것이다.
- 이후, for(User user : users) 에서 다음과 같은 추가쿼리 1개 가 나간다
select
o1_0.user_id,o1_0.id,o1_0.product
from
orders o1_0
where
o1_0.user_id in (1,2,3,4,5,6,7,8,9,10);- 장점
- 중복 데이터 방지 - User 는 한번만 로딩된다
- Pageable 을 지우너한다
- N + 1 문제를 완화 할 수 있따 (BatchSize) 로 N 개의 쿼리 대신 N/BatchSize 의 쿼리
5. 결론
N + 1 문제의 해결은 성능 최적화를 위한 첫번째 걸음이라 봐도 좋을만큼 중요하며 최적화의 여지가 많은 부분이다. FETCH JOIN 은 이를 해결할 수 있는 강력한 도구이지만, 중복 데이터, 너무 많은 데이터를 한번에 조회한다, 페이징이 불가능하다 등의 치명적인 단점이 존재한다.
그렇기 때문에 @BatchSize() 를 적용하여 Lazy Loading 의 단점을 보완하고 ,Pagination 을 활용하여 최적의 쿼리 개수를 유지하는 방법이 가장 효과적인 것 같다.
'SPRING' 카테고리의 다른 글
| Spring Security 기반 OAuth 2.0 & JWT 구현하기 (0) | 2025.03.25 |
|---|---|
| JPA 다건 조회 시 프록시 객체가 포함되는 원인 분석 - feat. Persistence Context 출력하기 (0) | 2025.03.12 |
| JPA SQL - 가독성 좋게 보기 (0) | 2025.02.19 |
| 프론트 컨트롤러와 DispatcherServlet (0) | 2025.01.09 |
| 스프링 빈 초기화·소멸 로직 : 인터페이스, Bean, @PostConstruct (0) | 2024.12.12 |



