
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Spring
- spring security
- lombok
- Google OAuth
- OAuth 2.0
- builder
- Volatile
- Dependency Injection
- 일급 객체
- java
- nestjs
- middleware
- 일급 컬렉션
- factory
- synchronized
- Today
- Total
HJW's IT Blog
Spring Batch 시스템에서 JdbcTemplate와 중복 데이터 처리 효율화 본문
1. 들어가며
Spring Batch 를 활용해 뉴스 기사를 외부 API 에서 수집하고, 이 기사는 관심사 별로 분류하여 DB에 저장하는 과정에서의 시행착오를 담은 글이다.
2. 문제 파악
기사 (Article)와 관심사 (Interest) 는 다대다 관계이다. 그렇기 때문에, 중간 테이블인 ArticleInterest 를 활용하여 저장하고자 하였다.
Batch 의 전체 프로세스는 다음과 같았다.
- Reader :
- DB에서 Keyword 를 읽는다
- Keyword는 Interest 와 연결된 단어이다.
- 기사를 조회할 때, Keyword 를 기반으로 조회한다
- Processor :
- 각
Keyword는 여러Interest와 연관되어 있을 수 있고, 하나의Interest는 여러Keyword를 가질 수 있기 때문에, 이 또한 중간테이블인KeywordInterest로 풀어내었다. - Processor 의 주된 역할은,
Keyword와 연관된KeywordInterest엔티티 조회,Keyword기반의Naver API조회 및 이를 Article - Interest 로 묶은List<ArticleInterestCreateCommand>로 반환하는 것이다
- 각
- Writer:
- Processor 에서 넘겨받은 List 를 실제 DB에 저장하는 역할을 한다.
- Article 에 대한 중복 검증이 일어난다.
이때, Writer에서 문제가 발생했다.
ArticleInterest 를 저장하는 과정에서 중복된 ArticleInterest 가 있을 경우, 예외가 발생하였다.
초기 Writer 메서드
@Override
public void write(Chunk<? extends List<ArticleInterestCreateCommand>> items) throws Exception {
// 기사 링크 수집 + mapping
Set<String> links = new HashSet<>();
Map<String, Article> linkToArticle = new HashMap<>(); // 캐시 역할
for (List<ArticleInterestCreateCommand> cmds : items) {
for (ArticleInterestCreateCommand cmd : cmds) {
links.add(cmd.article().getSourceUrl());
linkToArticle.putIfAbsent(cmd.article().getSourceUrl(), cmd.article());
}
}
// 이미 존재하는 기사 조회
Map<String, Article> existing = articleRepository.findAllBySourceUrlIn(links)
.stream().collect(Collectors.toMap(Article::getSourceUrl, a -> a));
// 존재하지 않는 기사 추출
List<Article> toSave = new ArrayList<>();
for (String link : links) {
if (!existing.containsKey(link)) {
toSave.add(linkToArticle.get(link));
}
}
// 기사 저장 및 mapping
articleRepository.saveAll(toSave).forEach(a -> existing.put(a.getSourceUrl(), a));
// UPDATE & INSERT
List<ArticleInterest> articleInterests = new ArrayList<>();
for (List<ArticleInterestCreateCommand> cmds : items) {
for (ArticleInterestCreateCommand cmd : cmds) {
Article article = existing.get(cmd.article().getSourceUrl());
Interest interest = cmd.interest();
articleInterests.add(new ArticleInterest(article, interest));
}
}
articleInterestRepository.saveAll(articleInterests); // 예외 발생
}3. 해결 방안 1 : 중복 검사
List<ArticleInterest> articleInterests = new ArrayList<>();
for (List<ArticleInterestCreateCommand> cmds : items) {
for (ArticleInterestCreateCommand cmd : cmds) {
Article article = existing.get(cmd.article().getSourceUrl());
Interest interest = cmd.interest();
if (!articleInterestRepository.existsByArticleAndInterest(article, interest)) {
articleInterests.add(new ArticleInterest(article, interest));
}
}
}
를 통해 미리 중복된 객체는 저장되지 않도록 사전 필터링 작업을 거쳤다.
하지만, 총 ArticleInterest 의 조합은, Article 수 (N) x 연관 Interest 수(M) 으로 굉장히 많았기 때문에, DB에 조회 쿼리를 너무 많이 날리는 문제가 발생하였다.
이 시점, 1000 개의 Article 의 저장에 8초의 시간이 걸렸다.
4. 해결방안 2 : On Conflict Do Nothing
지금 개발중인 서비스의 특성상, 해당 도메인 데이터의 정합성이 아주 중요한 수준은 아니라는 생각이 들었다.
뉴스 기반 구독 서비스로, 기사를 외부에서 수집하여 이를 서비스의 프론트에서 제공하는데, 만약 기사 한두개가 누락되거나 부정확 하여도 큰 문제는 없을 것이라 판단되었다.
그래서 찾아본 결과, ON CONFLICT DO NOTHING 이라는 SQL 옵션을 발견하게 되었고, 이를 적용해 보기로 하였다.
다만, JPA 는 해당 옵션에 대한 기능을 제공하지 않기 때문에, 직접 JdbcTemplate 의 raw query 로 작성하였다.
String sql = """
INSERT INTO article_interests (id, article_id, interest_id, created_at)
VALUES (?, ?, ?, ?)
ON CONFLICT (article_id, interest_id) DO NOTHING
""";
jdbcTemplate.batchUpdate(sql, articleInterests, 1000, (ps, ai) -> {
UUID id = UUID.randomUUID();
Instant now = Instant.now();
ps.setObject(1, id);
ps.setObject(2, ai.getArticle().getId());
ps.setObject(3, ai.getInterest().getId());
ps.setObject(4, Timestamp.from(now));
});4.1 추가 문제 발생: DataIntegrityViolationException 발생
기존에는 모두 JPA Hibernate 의 기능을 사용하기 때문에 Transaction commit 시점에 모든 Database 작업이 이루어 졌었다.
하지만, JdbcTemplate 을 사용하게 될 경우, 영속성 컨텍스트나 다른 Hibernate 의 기능을 사용하지 못한다.
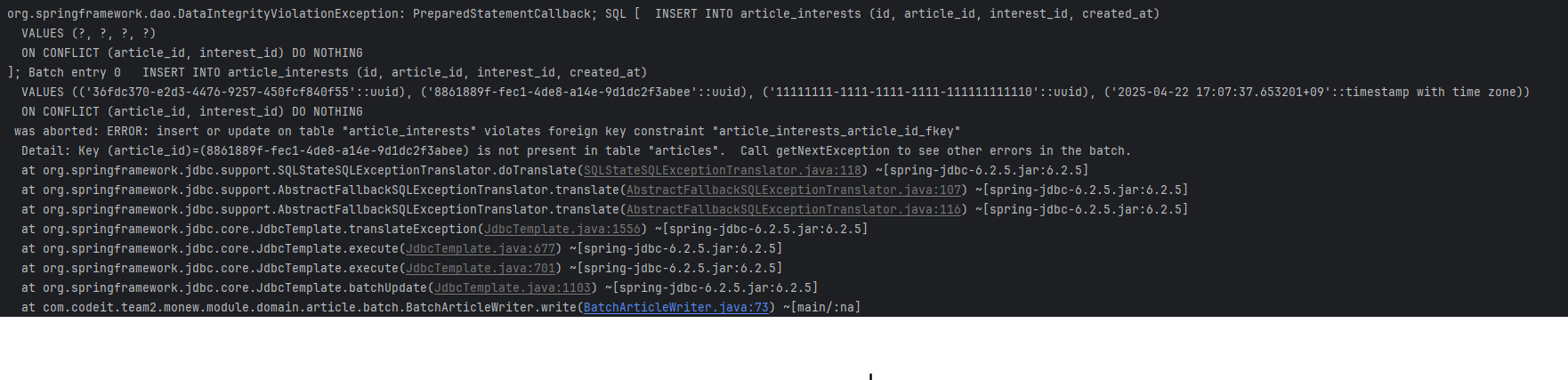
즉, JdbcTemplate 을 통한 쿼리가 발생하는 시점에, 조회한 Article 이 DB에 존재하지 않는 문제가 발생한 것이다.
미리 flush 를통해 조회한 article 들을 DB에 반영하고 이를 기반으로 작업하여 해결했다.
이를 해결하기 위해 Hibernate의 flush를 명시적으로 호출하여, 조회한 Article 데이터를 먼저 DB에 반영하도록 수정하였다.
결과적으로 성능이 1000 건의 데이터 처리에 8초 -> 4초로 단축되었다.
적용 전

적용 후
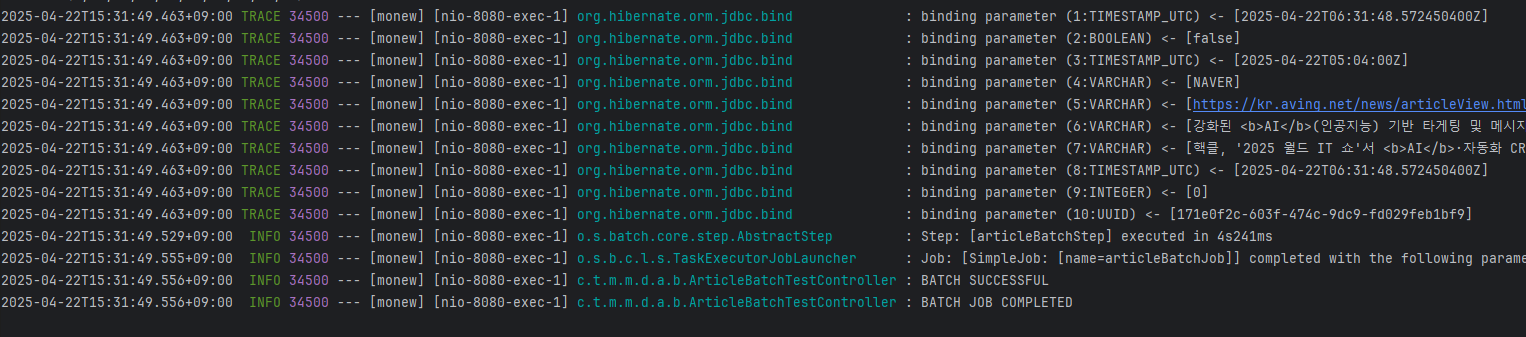
5. 정리
성능 개선에서 중요한 포인트는 구현하는 서비스, 도메인의 성능을 명확하게 파악하고 합리적인 타협점을 찾는것이 중요하다는 생각이 들었다.
이번 서비스에선, 데이터의 정합성을 조금 포기하는 대신 성능을 대폭 개선하였다.
또한 Spring Batch 에서 대량의 데이터를 처리할 경우, JPA 를 사용하는것 보다 네이티브 SQL 을 활용하는것이 더 좋은 선택일 수 있다는 생각이 들었다.
'SPRING' 카테고리의 다른 글
| Spring 테스트 격리와 트랜잭션: @Sql 삽입 데이터가 사라지는 이유 (0) | 2025.04.01 |
|---|---|
| [Spring Security] OAuth2.0 + JWT 로그인 구조에 Form Login 통합하기 (0) | 2025.03.26 |
| Spring Security 기반 OAuth 2.0 & JWT 구현하기 (0) | 2025.03.25 |
| JPA 다건 조회 시 프록시 객체가 포함되는 원인 분석 - feat. Persistence Context 출력하기 (0) | 2025.03.12 |
| Batch Fetching + Pagination으로 N + 1 해결하기 (0) | 2025.03.04 |



